Yinyu Nie1,2, Ji Hou3, Xiaoguang Han1,*, Matthias Nießner3
1Shenzhen Research Institute of Big Data, The Chinese University of Hong Kong, Shenzhen
2Bournemouth University
3Technical University of Munich
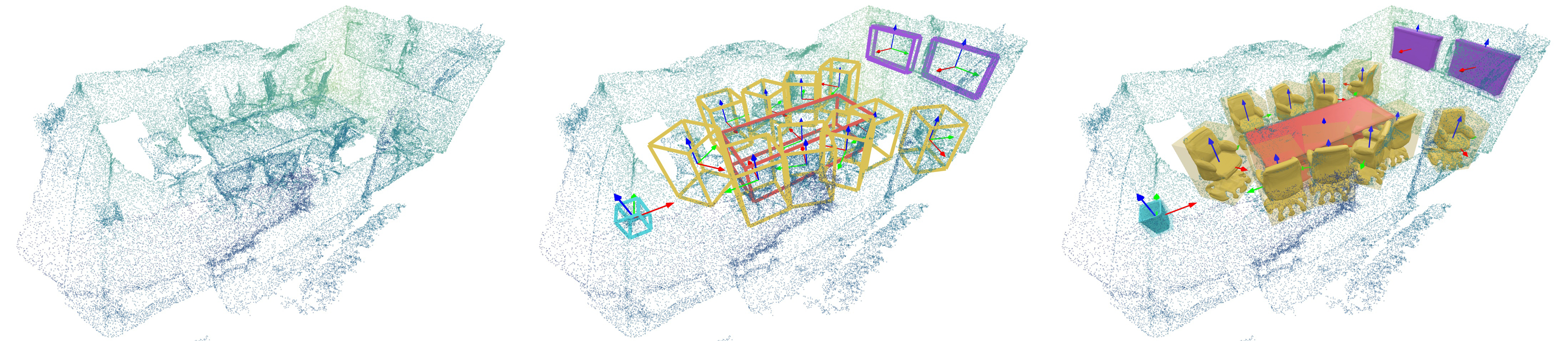
From an incomplete point cloud (Nx3) of a 3D scene (left), our method learns to jointly understand the 3D objects with semantic labels, poses (middle) and complete object meshes (right).
Abstract
Semantic scene understanding from point clouds is particularly challenging as the points reflect only a sparse set of the underlying 3D geometry. Previous works often convert point cloud into regular grids (e.g. voxels or bird-eye view images), and resort to grid-based convolutions for scene understanding. In this work, we introduce RfD-Net that jointly detects and reconstructs dense object surfaces directly from raw point clouds. Instead of representing scenes with regular grids, our method leverages the sparsity of point cloud data and focuses on predicting shapes that are recognized with high objectness. With this design, we decouple the instance reconstruction into global object localization and local shape prediction. It not only eases the difficulty of learning 2-D manifold surfaces from sparse 3D space, the point clouds in each object proposal convey shape details that support implicit function learning to reconstruct any high-resolution surfaces. Our experiments indicate that instance detection and reconstruction present complementary effects, where the shape prediction head shows consistent effects on improving object detection with modern 3D proposal network backbones. The qualitative and quantitative evaluations further demonstrate that our approach consistently outperforms the state-of-the-arts and improves over 11 of mesh IoU in object reconstruction.
Video
Method
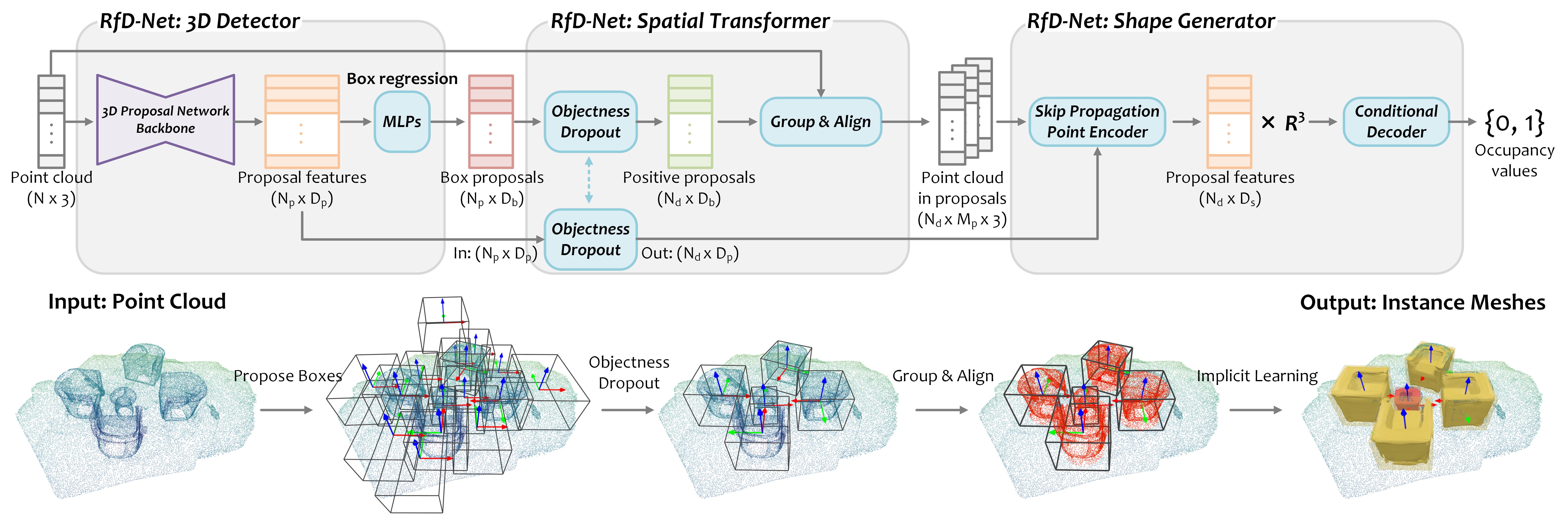
We illustrate the architecture of RfD-Net as above. Our method follows the basic principle of understanding 3D
scenes with ‘reconstruction from detection’. On this top, we devise the network consisting of a 3D detector, a spatial transformer and a shape generator. We build this architecture as generic as possible for learning instance shapes from point clouds, which should be flexibly compatible to modern point-based 3D proposal network backbones. Specifically, from an input point cloud, the 3D detector generates box proposals to locate object candidates from the sparse 3D scene. Then, we design a spatial transformer to select positive box proposals and group & align the local point cloud within for the next object shape generation. Shape generator independently learns an occupancy function in a canonical system to represent the shape of proposals.
Code and Data
Please find our code and data in Github.
Citation
If you are inspired by our work, please consider citing:
1 | @inproceedings{Nie_2021_CVPR, |