Yinyu Nie1,2,3, Xiaoguang Han2,3, Shihui Guo4, Yujian Zheng2,3, Jian Chang1, Jian J Zhang1
1Bournemouth University, 2The Chinese University of Hong Kong, Shenzhen
3Shenzhen Research Institute of Big Data, 4Xiamen University

From a single image (left), we simultaneously predict the contextual knowledge including room layout, camera pose, and 3D object bounding boxes (middle) and reconstruct object meshes (right).
Abstract
Semantic reconstruction of indoor scenes refers to both scene understanding and object reconstruction. Existing
works either address one part of this problem or focus on independent objects. In this paper, we bridge the gap between understanding and reconstruction, and propose an end-to-end solution to jointly reconstruct room layout, object bounding boxes and meshes from a single image. Instead of separately resolving scene understanding and object reconstruction, our method builds upon a holistic scene context and proposes a coarse-to-fine hierarchy with three components: 1. room layout with camera pose; 2. 3D object bounding boxes; 3. object meshes. We argue that understanding the context of each component can assist the task of parsing the others, which enables joint understanding and reconstruction. The experiments on the SUN RGBD and Pix3D datasets demonstrate that our method consistently outperforms existing methods in indoor layout estimation, 3D object detection and mesh reconstruction.
Video

Citation
If you are inspired by our work, please consider citing:
1 | @InProceedings{Nie_2020_CVPR, |
Method
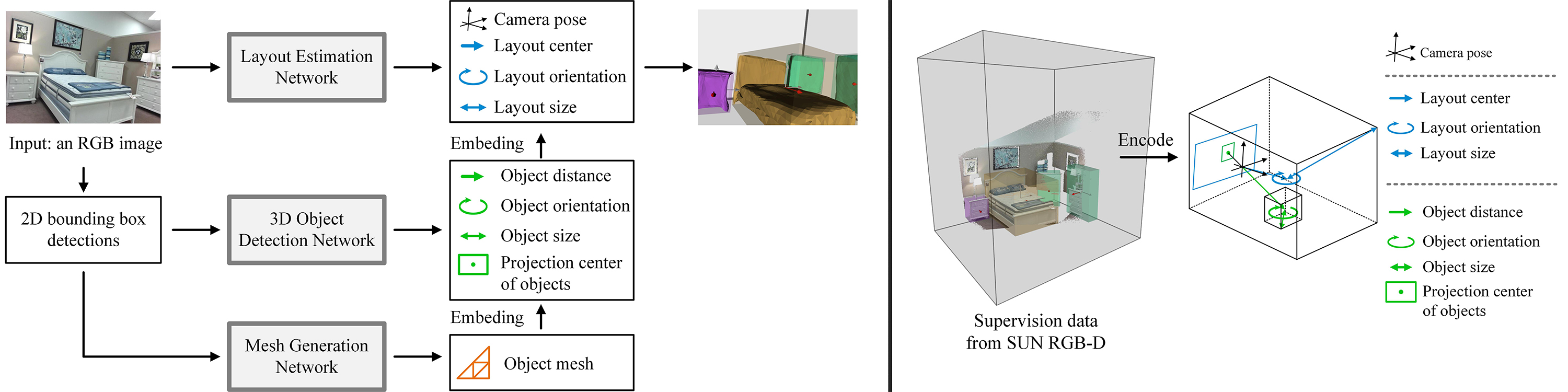
The network architecture follows a ‘box-in-the-box’ manner and consists of three modules: 1. Layout Estimation Network (LEN); 2. 3D Object Detection Network (ODN); 3. Mesh Generation Network (MGN). From a single image, we first predict 2D object bounding boxes with Faster RCNN. LEN takes the full image as input and produces the camera pose and the layout bounding box. Given the 2D detection of objects, ODN detects the 3D object bounding boxes in the camera system, while MGN generates the mesh geometry in their object-centric system. We reconstruct the full-scene mesh by embedding the outputs of all networks together with joint training and inference, where object meshes from MGN are scaled and placed into their bounding boxes (by ODN) and transformed into the world system with the camera pose (by LEN).
Code and Data
We provide source codes and related data of the project on https://github.com/yinyunie/Total3DUnderstanding