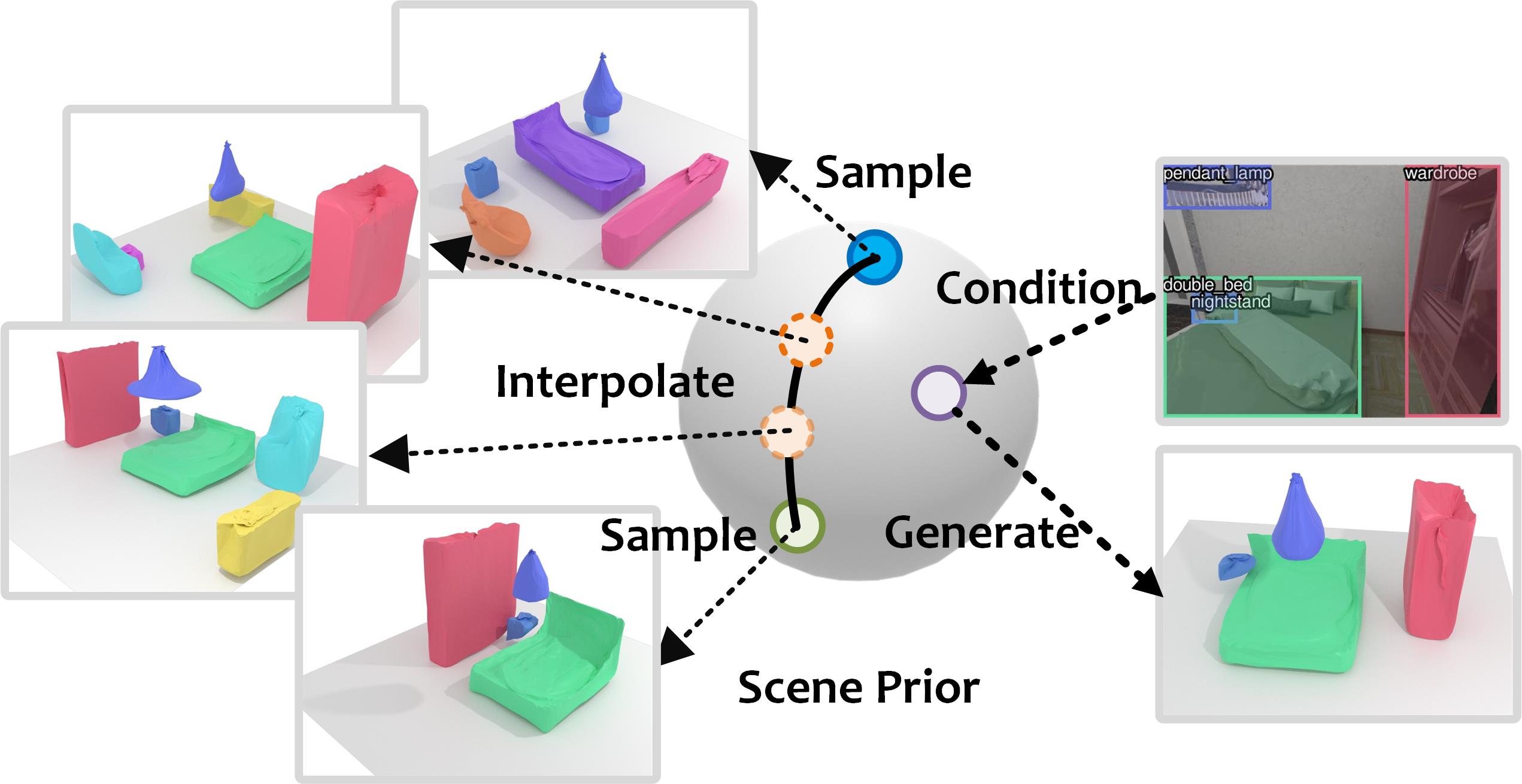






















Holistic 3D scene understanding entails estimation of both layout configuration and object geometry in a 3D environment. Recent works have shown advances in 3D scene estimation from various input modalities (e.g., images, 3D scans), by leveraging 3D supervision (e.g., 3D bounding boxes or CAD models), for which collection at scale is expensive and often intractable. To address this shortcoming, we propose a new method to learn 3D scene priors of layout and shape without requiring any 3D ground truth. Instead, we rely on 2D supervision from multi-view RGB images. Our method represents a 3D scene as a latent vector, from which we can progressively decode to a sequence of objects characterized by their class categories, 3D bounding boxes, and meshes. With our trained autoregressive decoder representing the scene prior, our method facilitates many downstream applications, including scene synthesis, interpolation, and single-view reconstruction. Experiments on 3D-FRONT and ScanNet show that our method outperforms state of the art in single-view reconstruction, and achieves state-of-the-art results in scene synthesis against baselines which require for 3D supervision.
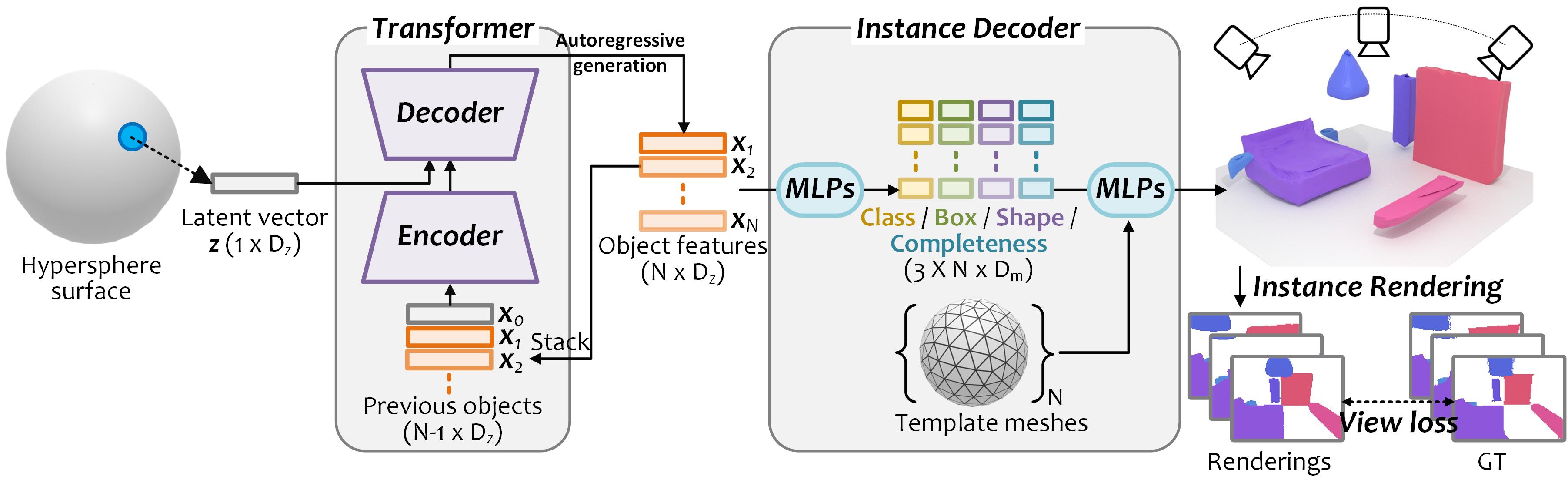
Overview of our approach.
Our method represents each scene as a learnable latent vector z on a hypersphere. To build mapping from the latent surface to the semantic scene space, we propose a permutation-invariant transformer to generate objects {xk} autoregressively conditioned on previous objects and z. For each object feature, we regress its object class label, 3D bounding box, shape feature and completeness score, which respectively represent the object layout, geometry, and the completeness of the output scene. We do not require 3D supervision, and instead leverage differentiable rendering with multi-view 2D instance masks supervision.
@article{nie2022learning,
title={Learning 3D Scene Priors with 2D Supervision},
author={Nie, Yinyu and Dai, Angela and Han, Xiaoguang and Nie{\ss}ner, Matthias},
journal={arXiv preprint arXiv:2211.14157},
year={2022}
}